0CTF中有一道opcode修改的题,当时觉得除了暴力尝试还原外没有什么更好的思路,结果后来看到了别人的write up,还真是暴力尝试~~
0x01 PyCodeObject
Python代码在运行时,将我们写的源码转换成字节码,再由python解释器来执行字节码。而字节码就是一个PyCodeObject对象。一个相应的对象如下:文件在/include/code.h
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| /* Bytecode object */
typedef struct {
PyObject_HEAD
int co_argcount; /*
int co_nlocals; /*
int co_stacksize; /*
int co_flags; /* CO_..., see below */
PyObject *co_code; /* 编译所得的字节码指令序列 */
PyObject *co_consts; /* Block中所有常量的元组 */
PyObject *co_names; /* 所有名字的元组 */
PyObject *co_varnames; /* 在本代码段中赋值,但没有被内层代码引用的变量*/
PyObject *co_freevars; /* 在本层引用,在外层赋值的变量*/
PyObject *co_cellvars; /* 本层赋值,且被内层代码段引用的变量*/
/* The rest doesn't count for hash/cmp */
PyObject *co_filename; /* python文件路径*/
PyObject *co_name; /* 函数名或类名*/
int co_firstlineno; /* Block所在的起始行*/
PyObject *co_lnotab; /* 字节码指令与pyc文件中的source code对应关系*/
void *co_zombieframe; /* 优化(see frameobject.c) */
PyObject *co_weakreflist; /* to support weakrefs to code objects */
} PyCodeObject;
|
从这个定义中,我们可以简单了解一下,该对象有哪些参数组成:
1 co_argcount,一个Code Block的参数计数。
作为萌新,这里再多提一下python中的几种参数形式,python中的参数形式可以分成位置参数和关键字参数两类,位置参数即参数所在的位置影响它被处理的逻辑,关键字参数即参数所在的位置与它的处理逻辑无关。
另一个概念是,Code Block,这个概念是说我们所写的Python代码中的每一个名字空间在编译时都会对应一个Code Block,每一个Block会创建一个PyCodeObject对象
那么这样的话,我们就可以理解这个参数做了什么,我们写一段代码来做个测试,看这样一段代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| def co_arg(fn):
print fn.__name__,fn.__code__.co_argcount
@co_arg
def f1():
pass
@co_arg
def f2(a):
pass
@co_arg
def f3(a,b):
pass
@co_arg
def f4(a,b=1):
pass
@co_arg
def f5(a,b,*c):
pass
@co_arg
def f6(a,b,*c,**d):
pass
|
执行结果如下:
>>f1 0
>>f2 1
>>f3 2
>>f4 2
>>f5 2
>>f6 2
OK,我们可以看到这个变量记录了函数的参数个数,但不记录tuple参数和dict参数
2 co_nlocals,一个Code Bloack的局部变量计数,包括所有参数和局部变量。
同样看如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def co_nlo(fn):
print fn.__name__,fn.__code__.co_nlocals
@co_nlo
def f1():
pass
@co_nlo
def f2(a):
pass
@co_nlo
def f3(a):
b=1
@co_nlo
def f4(a,*b,**c):
d=1
|
执行结果:
>>f1 0
>>f2 1
>>f3 2
>>f4 4
3 co_stacksize,运行这段Code Block需要的栈空间
剩下的解释就直接标注在上面的type结构中。
了解过PyCodeObject后,我们就可以来看看pyc,一般情况下,翻译的字节码会写入内存中,当程序结束后,会根据程序运行的方式来决定是否将字节码写入pyc或者其他格式的存储文件中。
我们来看一下一个简单的pyc文件。
0x02 pyc
我们编译如下代码到pyc来进行学习:
1
2
3
4
| def foo():
print 1
if __name__ == '__main__':
foo()
|
python -m py_compile hello.py
编译后的代码如下:
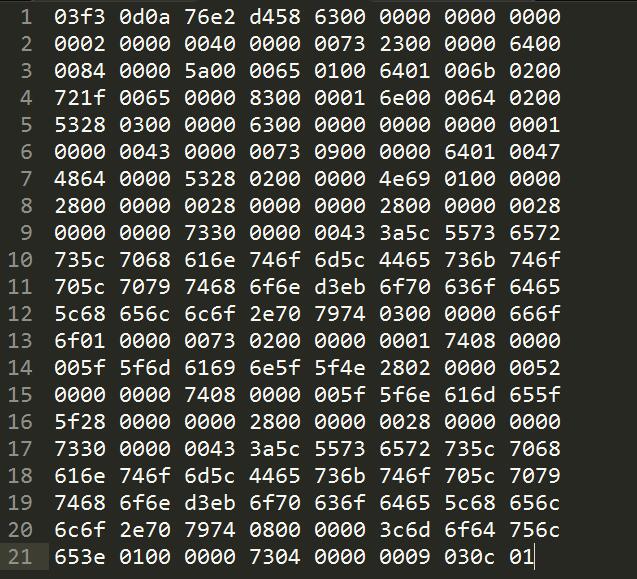
看上述pyc图,头4个字节,03f3 0d0a 是pyc的MAGIC数,用来表示python的版本。接下来的4个字节是时间。头声明完后的是一个Block的开头,即为63,后面的4个字节是PyObject中的argument数,这里为0,接着4个字节是nlocals,这里还是0。接着是4个字节的栈空间,0200 0000。
接着4个字节的flags 4000 0000。flag后面就是一些具体到代码的字节码。
开始是co_code,0x73,代表类型s(string),接下来的4个字节代表长度 2300 0000
使用小端模式,表示有35个字节长度。
接下来我们向后取35个字节长度,这时的字节码就可以对应上opcode,都2个字节对应相应opcode操作,如果操作后带有值,那么就在紧跟其后的4个字节中表示。
完整的版本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
| 03f3 0d0a 版本
76e2 d458 时间
63 block
0000 0000 argument
0000 0000 nlocals
0200 0000 栈空间
4000 0000 flags
73 类型 string
2300 0000 长度 35 bytes
64 00 00 LOAD_CONST 0
84 00 00 MAKE_FUNCTION 0
5a 00 00 STORE_NAME 0
65 01 00 LOAD_NAME 1
64 01 00 LOAD_CONST 1
6b 02 00 COMPARE_OP 2
72 1f 00 POP_JUMP_IF_FALSE
65 00 00 LOAD_NAME 0
83 00 00 CALL_FUNCTION 0
01 POP_TOP
6e 00 00 JUMP_FORWARD 0
64 02 00 LOAD_CONST 2
53 RETURN_VALUE
28 (
0300 0000
63
0000 0000
0000 0000
0100 0000
4300 0000
73
0900 0000
64 01 00
47
48
64 00 00
53
28 (
0200 0000
4e N
69 0100 0000 1
28 (
0000 0000
28 (
0000 0000
28 (
0000 0000
28 (
0000 0000
73 string co_filename
3000 0000
屏蔽敏感信息
74 t co_name
0300 0000
666f6f foo
0100 0000
73
0200 0000
00 01
74
0800 0000
5f5f 6d61 696e 5f5f
4e N
28
0200 0000
52 R
0000 0000
74
0800 0000
5f 5f6e 616d 655f5f
28 0000 0000
28 0000 0000
28 0000 0000
73 co_filename
30 0000 00
屏蔽敏感信息
74 co_name
0800 0000
3c6d 6f64 756c 653e <module>
0100 0000
73
0400 0000
0903 0c01 lnotab
|
解释一下,第一个block其实可以看成是main主程序的执行,第二个block就是foo函数中执行print的逻辑。
看这两张图,在对比我上面的字节码,应该就能懂了。
block 1
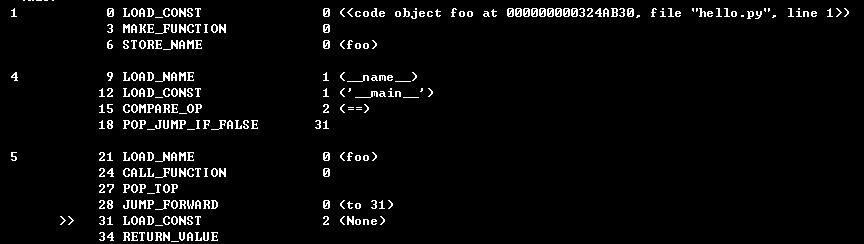
block 2

而opcode对应的操作,可以查看python目录下的opcode.py
0x03 一道0ctf题
在明白了上述原理后,可以参考这篇文章
http://0x48.pw/2017/03/20/0x2f/
